Article Text

Abstract
Randomised controlled clinical trials are widely considered the preferred method for evaluating the efficacy or effectiveness of interventions in healthcare. Adaptive trials incorporate changes as the study proceeds, such as modifying allocation probabilities or eliminating treatment arms that are likely to be ineffective. These designs have been widely used in drug discovery studies but can also be useful in health services and implementation research and have been minimally used. In this article, we use an ongoing adaptive trial and two completed parallel group studies as motivating examples to highlight the potential advantages, disadvantages, and important considerations when using adaptive trial designs in health services and implementation research. We also investigate the impact on power and the study duration if the two completed parallel group trials had instead been conducted using adaptive principles. Compared with traditional trial designs, adaptive designs can often allow the evaluation of more interventions, adjust participant allocation probabilities (eg, to achieve covariate balance), and identify participants who are likely to agree to enrol. These features could reduce resources needed to conduct a trial. However, adaptive trials have potential disadvantages and practical aspects that need to be considered, most notably: outcomes that can be rapidly measured and extracted (eg, long term outcomes that take considerable time to measure from data sources can be challenging), minimal missing data, and time trends. In conclusion, adaptive designs are a promising approach to help identify how best to implement evidence based interventions into real world practice in health services and implementation research.
- health services
- primary health care
- public health
- clinical trial
Data availability statement
Data are available upon request. Data will be available on reasonable request, pending appropriate agreements and institutional review board approval.
This is an open access article distributed in accordance with the Creative Commons Attribution Non Commercial (CC BY-NC 4.0) license, which permits others to distribute, remix, adapt, build upon this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited, appropriate credit is given, any changes made indicated, and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0/.
Statistics from Altmetric.com
Key messages
Adaptive trials are increasingly emerging as options to increase the efficiency and scale of interventions that could be tested in clinical medicine; while they could be used in translation of healthcare delivery interventions, they have had limited use in this context
In particular, adaptive trials could be well suited for health services research and implementation research approaches that drop inferior arms, adjust allocation probabilities, adjust sample size, or study multicomponent interventions
Simulation studies indicate that adaptive designs for two parallel group trials can have advantages over conventional, fixed non-adaptive designs (including decreasing required sample sizes), the length of the trial, and the precision of effect estimates, depending on the outcome measurement window
Adaptive trials will be more difficult to use in settings where outcomes are not rapidly retrievable or measurable from the data sources, where substantial data are missing, and when there are significant time trends
Introduction
In conventional fixed randomised controlled trials, participants are randomised to treatment groups and followed until outcomes are evaluated, generally using intention-to-treat principles. While these designs are widely considered the preferred method for evaluating the efficacy and effectiveness of healthcare interventions,1 their limitations have been well described.1 Most notable among these limitations is their relative inefficiency.2–4 In many traditional randomised controlled trials, in health services and implementation research, interventions to be tested are set at the beginning of the study, and regardless of what happens during the course of the study, neither treatment assignment or allocation probabilities are modified.2
By contrast, in adaptive randomised trials, outcomes are observed and analysed at prespecified interim time points and modifications to study design can be made based on these observations, including modifying randomisation strategies or dropping inferior treatment arms (figure 1).5 Adaptive multiarm designs might require fewer patients than traditional randomised controlled trials6 and could allow for the testing of multiple interventions with more efficiency, but they also have important caveats, most notably increasing trial and methodological complexity.7 The most common types of adaptive trial designs (in order) include: phase 2/3 studies that combine phase 2 and 3 trials, adaptive group sequential trials (which use interim stopping rules), biomarker adaptive trials (which adapt according to biomarkers), adaptive dose finding studies (which adjust allocation probabilities), pick-the-winner or drop-the-loser design (which drops inferior arms), and sample size re-estimation (which adjusts sample size based on interim data).6 8 Other types of adaptive designs and variations of these existing ones have also been used.9

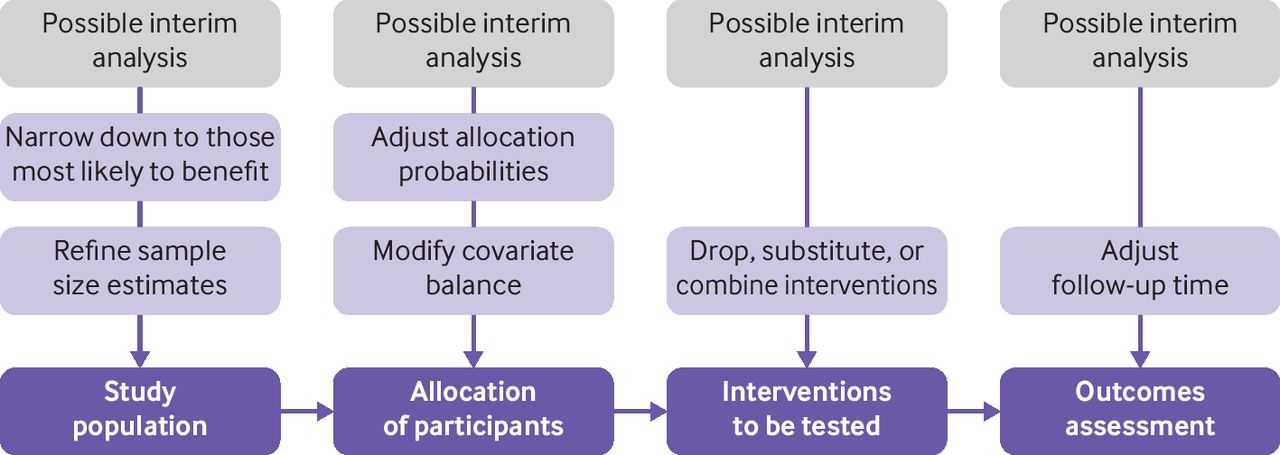{kind=link}
Overview of potential adaptive design options through interim analyses
While adaptive trials have been widely used in early phase clinical studies, particularly in oncology,10–15 they also appear well suited for research domains further along the translational research spectrum. Implementation science and health services research studies often seek to identify the most effective intervention, policy, or tool among a wide variety of possible strategies. Yet their use in these contexts remains extremely limited. Trials in this field typically evaluate healthcare delivery interventions for their real world effectiveness on health outcomes. As such, of the most common adaptive trial designs, those that adjust allocation probabilities, drop inferior arms, or adjust sample size would be particularly helpful in this type of research.16 17
In this article, we describe the potential advantages, disadvantages, and important considerations when applying these types of adaptive trials to implementation and health services research. We specifically consider: which interventions can be tested with adaptive designs; how eligibility criteria, enrolment procedures, and allocation probabilities can be modified; what outcomes can be evaluated and conducting interim analyses; and what the implications are on trial sample sizes and length of follow-up. Each consideration is outlined in table 1 and described in further detail throughout.
Overview of practical considerations for adaptive trials in health services or implementation research
Motivating examples
To illustrate advantages, disadvantages, and considerations of adaptive designs in implementation and health services research, we describe three motivating case examples: an ongoing, pick-the-winner adaptive randomised pragmatic trial of healthcare delivery interventions and two completed multiarm pragmatic trials. We also evaluate the two completed trials’ operating characteristics had they been conducted using an adaptive design that prospectively adjusts allocation probabilities during the trial. We focused on this type of design as illustration, because it is the most common adaptive design of those we believe could be useful in this field.8
Case example 1: NUDGE-EHR (adaptive, randomised pragmatic trial)
The NUDGE-EHR (Novel Uses of adaptive Designs to Guide provider Engagement in Electronic Health Records) study is a two stage, 16 arm, adaptive randomised trial with a pick-the-winner design that seeks to identify the most effective electronic health record tools for reducing prescribing of high risk drug treatments (NCT04284553).18 In stage 1, 201 primary care providers were randomised to usual care (81 providers) or in equal proportions to one of 15 electronic health record tools designed using behavioural principles (eight providers/arm; online supplemental figure S1). After an eight month follow-up, arms were ranked by their impact on prescribing (ie, discontinuation or tapering drug treatments of interest), using electronic health record data. The five best performing interventions were then selected. In stage 2, usual care providers in stage 1 were randomised in equal proportions to one of the selected arms or to continue to receive usual care; and stage 1 providers who were in one of the unselected arms were re-randomised in equal proportions to a selected arm or usual care.18
Supplemental material
Case example 2: MOTIVATE (fixed randomisation pragmatic trial)
The MOTIVATE (Mail Outreach To Increase Vaccination Acceptance Through Engagement) trial was a five arm, parallel group, pragmatic randomised trial testing whether the incorporation of behavioural science into mailed communication increased rates of influenza vaccination (NCT02243774).19 Here, 228 000 Medicare beneficiaries were randomly assigned to control (no contact) or to one of four active arms in which participants received letters that all included information about vaccination but which varied the signatory and prompts. Letter 1 was from the National Vaccine Programme Office; letter 2 was from the US Surgeon General; letter 3 was from the US Surgeon General and contained an implementation intention prompt (ie, asking patients to complete a plan for receiving the vaccine); and letter 4 was from the US Surgeon General and contained an active choice enhanced prompt for implementation (ie, asking patients to choose between completing a plan for the vaccine). The primary outcome was a binary outcome of influenza vaccination receipt in the four month follow-up, measured using insurance claims.
Case example 3: REMIND (fixed randomisation pragmatic trial)
The REMIND (Randomised Evaluation to Measure Improvements in Nonadherence from low cost Devices) trial was a four arm, parallel group, pragmatic randomised controlled trial that tested whether simple devices improved adherence to drug treatments (NCT02015806). This trial allocated 22 163 participants using drug treatments for cardiovascular or another non-depression condition in a 1:2:2:2 allocation ratio to control (no contact) or to receive one of three devices designed to help adherence. These devices included a strip with buttons to be toggled after taking each day’s dose, a digital timer cap, and a standard daily pillbox. The primary outcome was optimal adherence over 12 months after randomisation (binary outcome), measured using insurer claims.20 21
Comparing fixed and response adaptive randomized designs
To illustrate implications for sample size, study duration, and power that could be obtained using adaptive trial strategies, we compare the operating characteristics of the MOTIVATE and REMIND trials using the original design or outcome adaptive bayesian design. We considered three outcome scenarios with varying effectiveness across arms (table 2). These scenarios were selected because they were thought to have at least one case favouring each type of randomised controlled trial (ie, adaptive or fixed/conventional). Scenario 1 assumed different treatment effects across intervention arms. Conversely, scenario 2 would be favourable to an adaptive randomised controlled trial because one intervention arm was designed to be clearly more effective another arms, and scenario 3 would favour fixed randomisation because no intervention arm was superior to another intervention arm. We also varied the outcome measurement windows and number of interim analyses.
Changes in sample size for MOTIVATE and REMIND trials if designed as adaptive trials under varying assumptions
We chose these examples to demonstrate the impact of effectiveness, lengths of time needed to measure outcomes (ie, short term v long term) and number of interim analyses on sample sizes and trial duration. We otherwise used original trial assumptions for all scenarios. For MOTIVATE, we assumed that the 228 000 participants were allocated to five treatment arms in a fixed 10:2:2:3:3 ratio for the non-adaptive design, and that controls had a 65% vaccination rate. We then considered relative effect sizes of 5-10% compared with control. For REMIND, we assumed an allocation ratio of 1:2:2:2 for the non-adaptive design, 22 163 participants, a 2% rate of adherence in the control arm,20 and relative effect sizes of 5-8% versus control.
For further detail, see online supplemental section S1. Simulation findings, including estimated average sample sizes in each arm and average duration of the entire trials, are in table 2 and described throughout the following sections. For these simulations, we assumed that interim analyses would take 30 days; in practice, the time to conduct them can vary depending on the trial and trial oversight, although to our knowledge, this has not been precisely calculated and published.
Interventions appropriate for testing
Compared with traditional randomised controlled trials that include all interventions at the trial outset, adaptive trials can add, drop, or combine interventions on the basis of the results of interim analyses (ie, pick-the-winner or drop-the-loser designs). Interventions to be tested using adaptive designs are ideally assigned sequentially or discretely. In implementation and health services research, this means that interventions such as educational and counselling sessions, technologies, health insurance benefit structures, or checklists with discrete components are likely more suitable for adaptive trials. Accordingly, different devices (eg, REMIND) or different letters (eg, MOTIVATE) could be tested sequentially using adaptation. However, some interventions would be less ideal, notably those that cannot be applied sequentially. For example, interventions where all participants in one group are exposed simultaneously, such as an organisational change, would eliminate the ability to adapt.
Moreover, multicomponent interventions, such as those combining financial incentives with other modes of patient engagement, can also be tested in adaptive trials if intervention subcomponents are suitable for randomisation. Accordingly, investigators could reduce the number of interventions that continue to be tested over time. Adaptive trials could also allow researchers to evaluate individual parts of multicomponent interventions using regression modelling with each component being a factor in the analysis.18 Statistical models of the effects and interactions of single interventions allow the selection and prioritisation of promising multicomponent interventions. While researchers might not have as much power to evaluate individual components as studying the multicomponent intervention, when it is of particular interest to understand the impact of individual components, this approach might prove useful.
For instance, NUDGE-EHR used a pick-the-winner design to eliminate ineffective interventions after the first interim analysis and used a design to evaluate multicomponent interventions (eg, a follow-up message in addition to decision support).18 Similarly, had the MOTIVATE trial used an adaptive design, relevant letter features could have been compared, and based on interim analyses, resources could be concentrated on letters combining the most promising features. Additionally, for REMIND, ineffective devices could have been eliminated, as in scenario 1 where arm 4 was eliminated after the first interim analysis, or stage 1 (table 2).
Of note, interventions are not widely combined after interim analyses in adaptive trials presently, which is at least in part because multicomponent interventions are rarely evaluated in drug development. Conversely, many health services and implementation research trials evaluate multicomponent interventions; for instance, in studies aimed at drug treatment adherence, most effective interventions are multicomponent.22 23
Eligibility criteria, enrolment procedures, and allocation probabilities
To reduce required resources for a trial, adaptive trials can alter eligibility criteria to increase the likelihood of enrolment, adjust recruitment methodology, and modify allocation probabilities. This concept is similar to evaluating the degree of reach, or representativeness of participants willing to participate as an implementation outcome.24 25 So, in addition to altering which interventions are being tested, adaptive trials can change the ratio of participants allocated to each arm in subsequent trial stages (eg, from 1:1 to 2:1). An example is shown in MOTIVATE simulation scenario 1 where more individuals received effective treatments than they would have received in the original scenario (table 2; eg, 25 878 v 22 798 participants in arm 1 and 59 170 v 114 002 participants in the control arm).
Accordingly, in health services and implementation research, the most common data sources used are electronic health records, administrative claims, and self-report.23 26–28 For researchers wishing to adapt enrolment or eligibility criteria, electronic health records or claims data would be most helpful because they are routinely collected and would allow for adaptation without needing patient interaction. This would also reduce the amount of missing data when evaluating differences between those individuals who do and do not participate.25 For example, if REMIND had been adaptive, baseline characteristics of patients who agreed to use the devices (such as the number of drug treatments in their regimen) could have been used to change subsequent enrolment.
In adaptive trials, allocation probabilities can be easily altered in trials that enrol on a rolling basis. For trials that enrol participants all at the same time, such as REMIND or MOTIVATE, the recruitment strategy would need to be modified.1 29 In other words, adaptive trials can be designed to identify characteristics of those responsive to interventions and adjust accordingly (ie, a population enrichment design). For example, in REMIND, men responded better than women to the pillbottle strip; accordingly, if REMIND had been adaptive, subsequent stages after interim analyses could have preferentially allocated male patients to the pillbottle strip.
Allocation to treatment arms could also be adjusted to improve balance on baseline participant factors, such as sociodemographic characteristics, which might be particularly relevant for studies in health services or implementation research. Making such adjustments is understandably easier in trials with rolling recruitment but is also possible with simultaneous enrolment. For example, in MOTIVATE, the percentage of patients who receive the influenza vaccination in the previous season differed slightly between arms (ie, arm 5 had the lowest rate compared with the other arms), and while this imbalance was controlled for in modelling, a higher proportion of previously vaccinated patients could have been assigned to arm 5 to improve balance after interim analyses. Care must be taken for accounting for potential changes in the risk of the outcome for participants enrolled over time; if charges are large, these time trends could be a disadvantage of adaptive trials.
Choice of outcomes and interim analyses
In adaptive trials, the primary outcomes used for adaptation in interim analyses need to be rapidly retrievable for evaluation.10 For health services and implementation research, the need for rapid retrieval means that an information system is needed to capture the outcome for evaluation in as near to real time as possible. The time needed for the interim analyses itself largely depends on the complexity of the data being collected and on data vetting before interim decisions. Of the main data sources used in this field, the lag time for accessing administrative claims data can sometimes preclude their use in interim analyses, particularly for medical claims, which take months to fully adjudicate; pharmacy claims are complete within days and might be more easily used.27 To access information on emergency room visits or hospital admission outside of medical claims, researchers might consider using admission-discharge-transfer feeds within electronic health records, which are also available quickly. Of course, researchers or practices receiving these data through agreements might experience further delays but this process would be less problematic for trials conducted and evaluated within insurance systems.27 30
By contrast, electronic health records data are recorded in real time and can be retrieved as soon as data are recorded.31 They might therefore be useful for rapidly observing outcomes in adaptive trials. In NUDGE-EHR, adaptation occurred based on prescribing data from electronic health records. Other outcomes useful for adaption could include biometric data, such as blood pressure, weight, specific lab test results (eg, glycated haemoglobin A1c), or receipt of laboratory tests or preventive screenings such as colonoscopies. Similarly, patient reported information from connected devices might also provide data appropriate as outcomes for adaptive trials in this field.26 Examples include accelerometer data from smartphones about physical activity, home blood pressure or glucose monitors, especially if delivered via Bluetooth connections that require minimal patient manipulation and can be quickly acquired. Their increasing real time data availability could provide avenues for future adaptive trials.
However, missing data can pose a substantial issue for adaptive trials, which is typically more problematic for patient reported outcomes or those that require patient follow-up in person (eg, cholesterol).32 33 This is a potential disadvantage of using adaptive trials in health services research, given that many trials are designed to be pragmatic and therefore could have higher rates of missing data than drug development studies.34 Similarly, high rates of dropout or loss to follow-up, while challenging for any trial, might actually pose a greater challenge for adaptive trials because missing data can therefore produce biased parameter estimates and participant allocation. Thus, choosing outcomes (eg, prescribing or ordering or presence or absence of diagnoses) that are less subject to having missing data could be particularly important for trials in this space. Of note, although the outcomes chosen for the NUDGE-EHR, MOTIVATE and REMIND simulations were binary, outcomes used for adaptation might take other forms, such as being continuous, depending on data completeness.
It is possible to incorporate other slower data sources where outcomes cannot be measured rapidly in an adaptive trial. In NUDGE-EHR, while the outcome for adaptation is prescribing that is assessed using electronic health record data, long term outcomes including medication filling and all cause hospital admissions can be assessed at the end using administrative claims data. Put into context, the length of the outcome (described in the next section) might have a greater influence on the ability to conduct an adaptive trial than being able to measure outcomes rapidly, but both are important considerations.
Finally, a common question for adaptive trials is how many interim analyses should be conducted. In practice, interim analyses most commonly occur one to three times throughout adaptive trials, because of cost and duration.8 Increasing the number of interim analyses typically does not translate into dramatic gains in efficiency and accuracy of final findings. In fact, more frequent evaluations of data to stop interventions for futility can decrease power of the final analysis.35 Also, when most participants are already enrolled, it becomes difficult to improve efficiency based on interim decisions, unless investigators allow for variations of the individual intervention and longitudinal modelling of outcomes over time.36 Other researchers have also provided calculations that help reduce the delay in interim analyses where, for example, recruitment is continued during interim analyses.37
Required sample size and length of follow-up
The overall sample size can be adjusted during interim analyses to ensure desired power when effect estimates are different than originally contemplated (ie, a sample size re-estimation design).10 Although difficult in practice, sample size re-estimation could in principle also be used to refine the intraclass correlation for cluster randomised trials.38 However, given that cluster trials are commonly used in this field and that intraclass correlations contribute substantially to underpowered trials, this remains an area of interest.38
In MOTIVATE and REMIND, reductions in necessary sample size depended on the effectiveness of the interventions but suggested that sample sizes could have been smaller for each adaptive approach compared with traditional approaches when some interventions were more effective than others (table 2). For example, scenario 2 in MOTIVATE had the smallest relative total sample size (30% of the original trial) because one arm was much more effective than others. Scenario 3 in MOTIVATE was no different than the original in expected sample size because each active arm had the same effectiveness, and thus on average no differential allocation was possible during interim analyses.
The precision of effect estimates for each scenario for an adaptive trial that adjusts allocation probabilities is shown in online supplemental table S1. For MOTIVATE, this scenario suggests modest changes in precision despite smaller overall sample sizes for scenarios 1-3. For REMIND, because of the smaller overall sample size, we observed increased standard errors in scenario 1-3. This loss of precision in the estimates, however, did not translate in a loss of power in the overall trial decisions. When we repeated scenarios 1-3 with a shorter follow-up time, the length of follow-up would reduce precision, although still require smaller sample sizes than the original trial. Of note, the differences between MOTIVATE and REMIND in relative changes in sample size are largely due to baseline assumptions about the rate of outcomes in the control arms. For consistency, we chose to use the original assumptions and power calculations; operating characteristics would differ (and suggest larger necessary sample sizes) if recalculated based on actual trial results, which showed smaller effect sizes. We also considered additional power calculations for the MOTIVATE trial with a substantially reduced sample size (ie, n=6300) to reduce the potential influence of large sample sizes on precision. We tuned the bayesian adaptive design to have a similar average sample size and power as fixed randomisation when all the interventions share the same effectiveness (scenario 3). In these simulations, when some interventions are more promising than others (scenarios 1 and 2), the considered bayesian adaptive design has higher power with a lower average sample size (online supplemental table S2).
Similarly, if NUDGE-EHR had been a 16 arm, parallel group, non-responsive adaptive trial, we estimate that >1 50 000 patients (from about 6000 physicians) would be needed to achieve equivalent power (ie, probability of detecting positive effects with significant findings) under the same assumptions.
One important limitation of adaptive trials is that the use of long term outcomes for adaptation could greatly extend the trial duration. In MOTIVATE and REMIND, the primary outcomes (influenza vaccination receipt over four months and drug treatment adherence over 12 months, respectively) were relatively long term outcomes. Thus, if the outcomes in the simulation were measured over the same window as in the original trials, an adaptive design would extend time needed for the trial (table 2).
Alternatively, if the outcome measurement windows were modified as in table 2, the trial length could be preserved while reducing sample size. For example, in REMIND, a 12 month follow-up was used, being a common interval for adherence studies.23 39 However, the timeframe could have been compressed with outcome differences being measured over a shorter time frame (eg, three months) as shown in table 2. Furthermore, these are average durations and therefore could be shorter, especially with only one interim analysis and in situations where one arm is superior. As a result of setting the duration of the REMIND trial to match the original trial (12 months), more participants were randomised to the control arm; regardless, the overall necessary sample size was still lower. Of course, modifying the outcome measurement windows could affect the ability to observe the estimated effect size, so this may not always be appropriate.
Summary of potential strengths and limitations of adaptive trials
Adaptive trials are increasingly emerging as options to increase the efficiency and scale of interventions tested in clinical medicine. These designs could also be more widely used to potentially support more efficient evaluation and translation of healthcare delivery interventions. To our knowledge, previous work has not illuminated the extent to which adaptive trials could be specifically applied within implementation and health services research. Approaches that adjust allocation probabilities, drop inferior arms, or adjust sample size might also be well suited for health services and implementation research. The adaptive implementation of the MOTIVATE and REMIND trials suggest some advantages of adaptive trials but also illustrate potential disadvantages, including an impact on precision and potential for increasing average trial duration.
When considering other types of trials that also allow for the testing of numerous interventions, adaptive trials have several advantages. For example, factorial designs have been used in implementation research40 41 but have their own limitations, such as that all combinations of interventions studied must be implemented and having more than two intervention factors can be complex. Sequential Multiple Assignment Randomised Implementation Trial (SMART) designs are also increasingly being used, yet fundamentally are a special case of factorial designs involving multistage randomisations to modify the intervention for participants who already received the intervention if the first stage intervention was unsuccessful.41 42 Unlike adaptive designs, SMART designs do not adjust overall sample size or allocate new participants to study arms, unlike the broader set of possible adaptive trials.
Adaptive trials still have hugely important disadvantages in health services and implementation research, most notably the need for rapidly measurable and retrievable outcomes to not substantially increase the length of the trial. In addition, high rates of participant dropout or using outcomes for interim analyses susceptible to missing data might create more problems than in traditional randomised trials because they could lead to biased estimates of effectiveness and allocation probabilities. Similarly, considerable temporal trends can also be an limitation for adaptive designs, but some solutions do exist to resolve this and not all adaptive designs are affected equally, although designs that adjust allocation probabilities might be less suited in this scenario.9 43 When enrolment of study participants is simultaneous or even very fast, adaptative trials will also provide substantially less usefulness. Finally, when using outcome adaptive randomisation, researchers should establish the operative characteristics of the design by conducting simulations of the trial under a set of meaningful possible cases.44
Conclusion
Leveraging adaptive trials for health services and implementation research could present unique opportunities to improve public health, rigor, and conduct of pragmatic trials, and more rapidly facilitate delivery of optimal healthcare. Even in health services and implementation research settings, conducting randomised trials is expensive, so identifying ways to rigorously evaluate interventions faster will enhance the translation of evidence based interventions into real world practice.
Data availability statement
Data are available upon request. Data will be available on reasonable request, pending appropriate agreements and institutional review board approval.
References
Supplementary materials
Supplementary Data
This web only file has been produced by the BMJ Publishing Group from an electronic file supplied by the author(s) and has not been edited for content.
Footnotes
JCL and NKC are joint first authors.
Twitter @jlauffen
Contributors JCL and NKC had overall responsibility for the design and drafted the manuscript. MR and SV contributed to the design and interpretation of the manuscript and conducted the simulation analyses and revised the manuscript for intellectual content. RJG contributed meaningfully to the design and interpretation of the manuscript and revised the manuscript for intellectual content. LT contributed to the design and interpretation of the manuscript and supervised the review and simulations. All authors approved the final manuscript. The corresponding author attests that all listed authors meet authorship criteria and that no others meeting the criteria have been omitted. JCL is the guarantor of the study.
Funding Research reported in this publication was supported by the National Institute on Aging of the National Institutes of Health (award numbers R33AG057388 and P30AG064199). JCL was also supported by a career development grant (K01HL141538) from the National Institutes of Health. LT and SV received support from the National Institutes of Health grant R01LM013352. The funders had no role in considering the study design or in the collection, analysis, interpretation of data, writing of the report, or decision to submit the article for publication.
Competing interests All authors have completed the ICMJE uniform disclosure form at www.icmje.org/disclosure-of-interest/ and declare: support from the National Institute on Aging of the National Institutes of Health for the submitted work; no financial relationships with any organisations that might have an interest in the submitted work in the previous three years; no other relationships or activities that could appear to have influenced the submitted work.
Patient and public involvement Patients and/or the public were not involved in the design, or conduct, or reporting, or dissemination plans of this research.
Provenance and peer review Not commissioned; externally peer reviewed.
Supplemental material This content has been supplied by the author(s). It has not been vetted by BMJ Publishing Group Limited (BMJ) and may not have been peer-reviewed. Any opinions or recommendations discussed are solely those of the author(s) and are not endorsed by BMJ. BMJ disclaims all liability and responsibility arising from any reliance placed on the content. Where the content includes any translated material, BMJ does not warrant the accuracy and reliability of the translations (including but not limited to local regulations, clinical guidelines, terminology, drug names and drug dosages), and is not responsible for any error and/or omissions arising from translation and adaptation or otherwise.